





Fire praktiske use cases for industriell DataOps
Bli bedre kjent med hvordan du kan utnytte en industriell DataOps-løsning gjennom fire praktiske use cases.

De fleste produksjonsbedrifter kjenner til fordelene ved å utnytte industrielle data for å forbedre produksjonen og spare kostnader. Mange har allerede testet i liten skala, men utfordringen er å oppskalere funksjonene til å inkludere hele anlegget. Det er flere årsaker til dette. Integrasjonsprosjekter kan være tidkrevende og dyre, bedriften er bekymret for å utsette driftssystemer for cybertrusler, og de mangler ansatte med de rette ferdighetene for å kunne gjennomføre prosjektet.
Bakgrunnen for utfordringene er at det er vanskelig å integrere datastrømmer på tvers av applikasjoner. Dette gjelder spesielt miljøer med mange ulike systemer, fra ulike leverandører, som er bygd opp med tilpasset koding og skripting. Standardisering av datamodeller, flows og nettverk er hardt arbeid. I motsetning til et kontormiljø med en håndfull systemer og databaser, kan en fabrikk eller anlegg ha hundrevis av datakilder. Disse er fordelt på maskinkontrollere, PLS’er, sensorer, servere, databaser, SCADA-systemer og historians, – bare for å nevne noen.
Industriell DataOps er en ny tilnærming til dataintegrasjon og administrasjon. Løsningen gir et programvareverktøy for dokumentering, styring og sikring av data, – fra detaljnivå på hver enkelt maskin, til hele linjer og anlegg, og opp på bedriftsnivå. Industriell DataOps kommer med et eget dataabstraksjonslag, eller hub. Dette sørger for sikker innsamling og distribusjon av standard datamodeller på tvers av lokale og skybaserte applikasjoner.
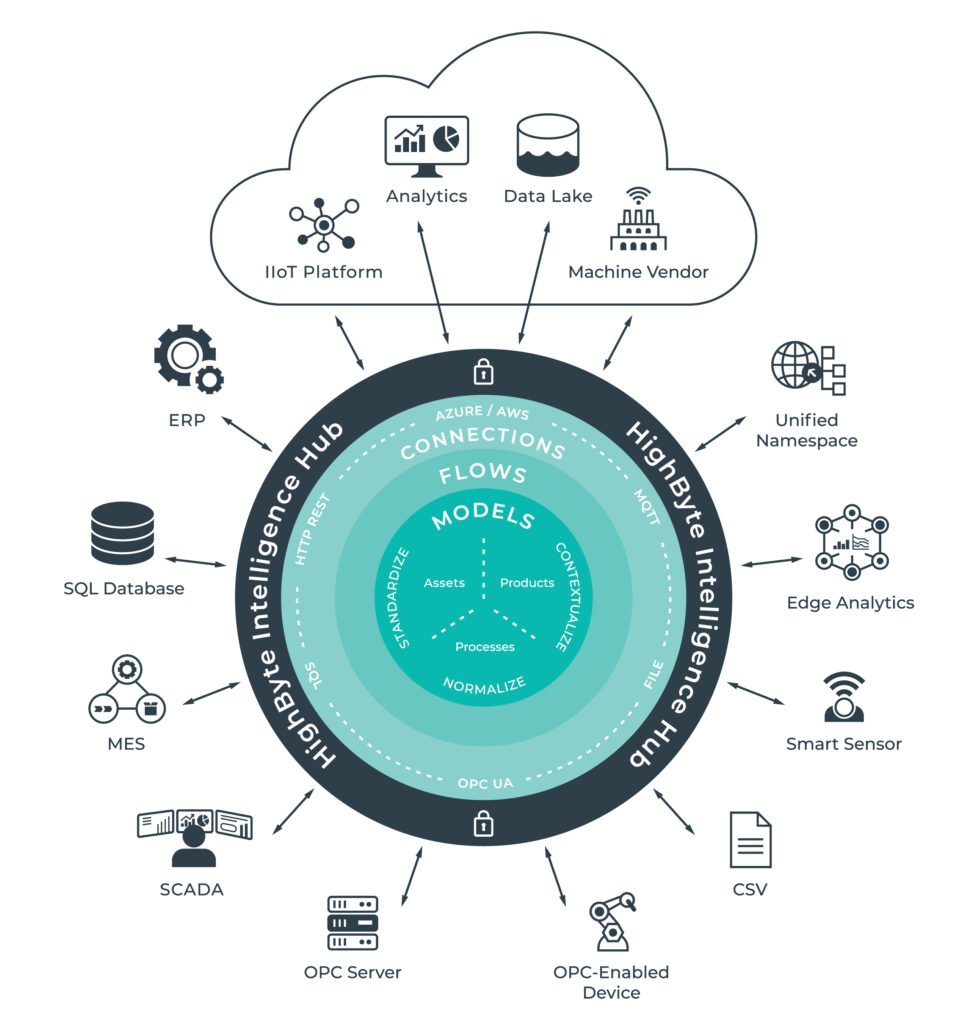
De fire use casene nedenfor illustrerer hvordan industriell DataOps kan integrere operasjonssystemene med IT-systemene dine, i tillegg til eksterne leverandører.
1. «Jeg må akselerere og skalere bruken av Analytics»
La oss si du har flere linjer med sprøytemaskiner. Du vil kjøre analyse som sammenligner 20 datapunkter fra hver linje for å måle KPI’er og OEE, for å optimalisere ytelsen på alle linjene. Problemet er at maskineriet er fra ulike leverandører, og kjøpt med tiårs mellomrom. Kontrollerne er også fra ulike leverandører, og har blitt modifisert og tilpasset gjennom årene, – i likhet med databasene de er koblet til.
Til tross for forsøk på å standardisere og integrere kritiske aspekter ved denne infrastrukturen, varierer konteksten og datastrukturene. Selv om alle bruker trykk-, temperatur- og optiske sensorer, varierer leverandører, teknologier, kommunikasjonsprotokoller og til og med måleenheter.
Å ta fatt på et «fjern-og-erstatt»-prosjekt er både kostbart og fører til nedetid, og å skrive tilpasset kode er tidkrevende. I stedet kan maskinenes OPC UA-tagger kobles til standard informasjonsmodeller i en industriell DataOps-hub. Huben kjører på en rekke plattformer «on edge», fra en single-board IoT gateway, Raspberry Pi og industrial switch, til en hvilken som helst Linux-enhet gjennom Windows 10 og Windows Server-plattformer. For skalerbarhet, isolasjon og sikkerhet, kan huber installeres på maskin-, linje- eller anleggsnivå.
Nå har sprøytemaskinene strømlinjeformet, optimalisert data. OT-personell kan enkelt levere data videre til lokale systemer i nettverket, eller til Data Scientists som er avhengig av skybaserte systemer for AI og annen avansert analyse. Datamodeller er fullstendig kontekstualiserte og standardiserte før de sendes til skylagring. Det betyr at Data Scientists, som normalt sett bruker 80% av tiden på å rense og forberede data, kan komme rett i gang med dataforskning. Båndbredden og skylagringen reduseres, og tiden brukt på Analytics akselereres kraftig.
2. «Jeg trenger ekstern visualisering, og vil utføre analyse på tvers av flere anlegg.»
I industrier som papir og masse er datastrømmer fra de forskjellige delene av prosessen ulike. Fra «våte» kontinuerlige prosesser, til hybrid batch og emballasjeprosesser. Det samme gjelder bransjer som kjemikalier og næringsmiddel.
Denne type produksjon byr på flere utfordringer. Data må integreres fra flere systemer på tvers av anlegg, og bedriften er avhengig av tekniske support-team på hvert sted. Mange bedrifter velger derfor å ha ett, sentralt ingeniør- og IT-team. Dette teamet trenger tilgang til data for å kunne overvåke, vedlikeholde og optimalisere ressurser for å oppfylle bedriftsomfattende mål.
For å kunne gjøre analyse på dette nivået definerer det sentrale ingeniør- og IT-temaet enhetlige modeller, og sender dem til de ulike anleggene. Der kan OT-personell installere modellene i en edge-native industriell DataOps-hub.
Ingeniører kartlegger sine lokale datapunkter til standardmodellene etter hvert som systemer endres eller legges til. Dersom et nytt anlegg anskaffes, kan data også enkelt kartlegges til modellene. Som resultat unngår bedriften nedetid forårsaket av tradisjonelle metoder eller «fjern- og erstatt»-prosjekter.
Nå kan operative brukere fylle ut datamodeller og opprettholde forbindelser uten å skrive en eneste linje med kode, mens Data Scientists mottar enhetlige data av høy kvalitet. Analytics-syklustiden akselererer, og vi er i gang med digital transformasjon på bedriftsnivå.
3. «Jeg trenger å distribuere industriell data til flere bedriftssystemer.»
Produksjonsbedrifter kan ikke kun sende data vertikalt fra sanntidssystemer til hovedkontoret. Datastrømmer må kunne bevege seg på tvers av ulike anlegg- og bedriftssystemer. Disse systemene inkluderer SCADA, MES, ERP, laboratorier/systemer for kvalitetssjekk, oversikt over ressurser, vedlikeholdssystemer, overvåkning av cybertrusler, ulike dashbord, regnearkapplikasjoner, og selvsagt IIoT-infrastruktur som muliggjør Analytics, Machine Learning og AI.
I flere tiår har integrasjoner blitt gjort med API’er og tilpasset koding/skripting fra applikasjon til applikasjon, i stedet for et enhetlig miljø som alle datakilder flyter gjennom. Denne tilnærmingen til API’er begraver koden inne i applikasjonen, og gjør integrasjonen vanskelig å vedlikeholde. Uunngåelige endringer i produkter, automatisering og bedriftssystemer kan «bryte» integrasjoner. Dette kan resultere i uoppdagede dårlige, eller manglende data i flere uker eller måneder.
Industriell DataOps forhindrer at slike sammenbrudd oppstår fordi integrasjoner ikke lenger skjuler seg i tilpasset kode mellom applikasjoner. I stedet vedlikeholdes alle gjennom en løsning som gir et felles abstraksjonslag. Med systemer koblet sammen gjennom én enkelt integrasjonshub, får OT-personell et fleksibelt miljø, hvor de proaktivt kan administrere og distribuere data.
Nå har bedriften en raskere, enklere og mer robust måte å etablere og vedlikeholde integrasjoner, med en løsning som gir datasynlighet, vedlikehold, dokumentasjon, styring og sikkerhet.
4. «Jeg må trygt gi kundene data fra maskinene mine.»
Maskinbyggere står overfor kontinuerlige utfordringer med å redusere tid og kostnader som brukes på å utvikle, integrere og vedlikeholde maskiner. Smidighet og fleksibilitet er nøkkelen til å forhindre tid- og kostnadsoverskridelser. Dette er spesielt viktig når systemene skal integreres med utstyr som transportører, roboter, drivere og HMI/SCADA-systemer på kundens anlegg. Tradisjonelt sett innebar denne integrasjonen å tilpasse maskinkode eller ladder logic-programmering for å kunne støtte kundens systemer, – eller å be kunden om «å finne ut av det».
Nå, med industriell DataOps, kan leverandøren standardisere programmeringen, og utføre de nødvendige tilpasningene gjennom informasjonsmodellering i huben. Når kunden trenger å sende «disse fem datapunktene til SCADA-systemet, disse ti til MES-systemet, og disse syv til skyløsning koblet mot bedriftssystemet», vil leverandører enkelt være i stand til å definere modellene og rute informasjonen.
Med Industriell DataOps kan maskinbyggere koble seg mot produksjonskunders huber, og dermed mot HMI/SCADA, MES og andre systemer. Muligheten til å tilby fjernovervåkning, diagnostikk, OEE og prediktivt vedlikehold i alle skalaer gir stor verdi til kundeforholdet.
Når informasjon er i en standardform som er enkel å vedlikeholde, får alle parter bredere integrasjon. Enten det er på ett enkelt anlegg, flere anlegg, eller eksternt gjennom bedriftsorganisasjonen eller eksterne partnere.
Artikkelen er originalt skrevet av John Harrington ved HighByte. Les den her.








